HTTP.SYS High Performance Tuning
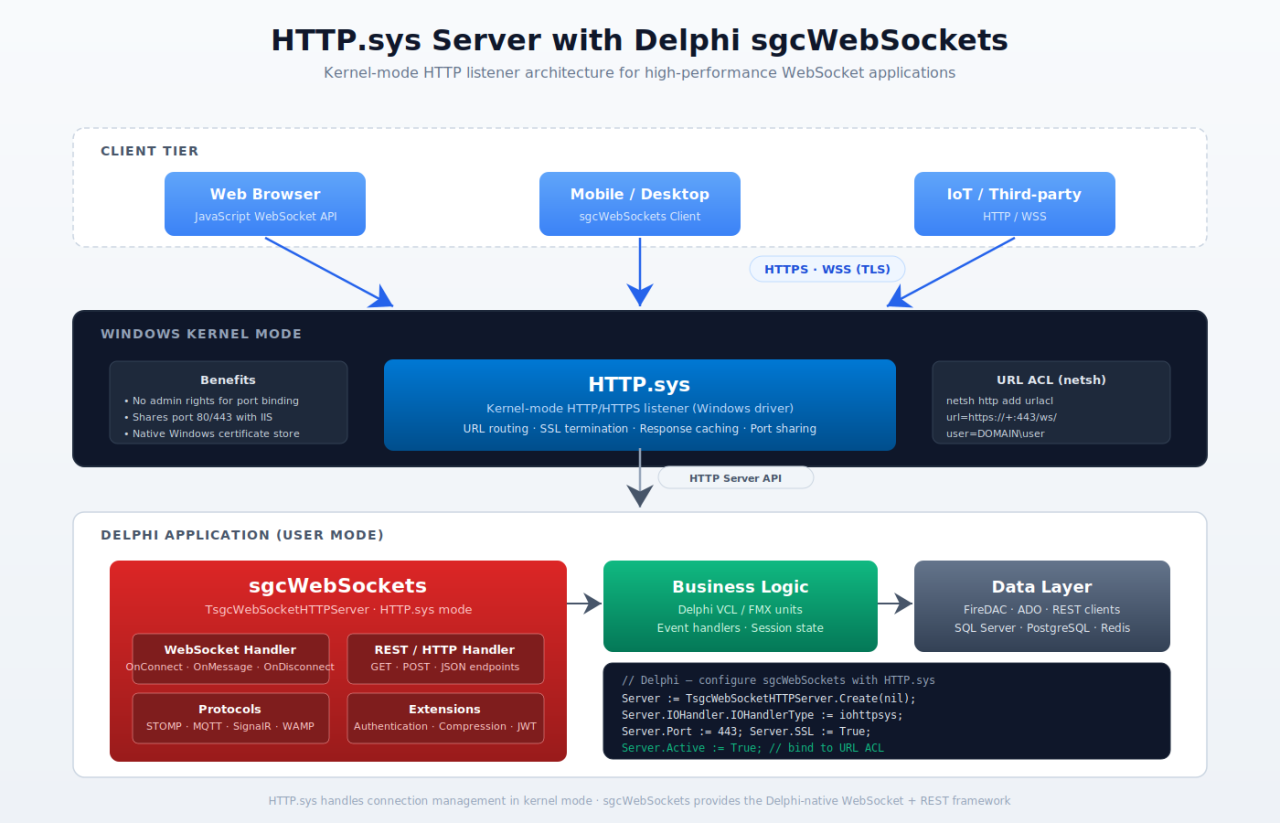
Starting with sgcWebSockets 2026.5.0, the TsgcWSServer_HTTPAPI component exposes a new published property, FineTune, typed as TsgcServerHTTPAPI_FineTune. It groups every low-level kernel-mode knob that influences how the Windows HTTP Server API (http.sys) queues, dispatches, and completes requests. Until now those knobs either didn't exist on the component or were hardcoded — now they are published, persisted with the form, and tunable at design time.
The FineTune property is a TPersistent container with four sub-properties: QueueLength, SkipIOCPOnSuccess, OperatingMode, and HighPerfAcceptsPerWorker. Every one defaults to a value that preserves existing behavior, so upgrading to 2026.5.0 requires zero code changes; you opt into each tweak individually when a specific workload demands it.
The FineTune Properties
QueueLength : ULONG (default 1000)
What it does. Wraps the HttpServerQueueLengthProperty kernel setting. It controls how many pending requests http.sys will hold in its kernel-mode queue before the server has dequeued them. When the queue is full, the kernel answers new connections with 503 Service Unavailable directly, without ever reaching user mode.
What it improves. On bursty workloads — thousands of IoT devices reconnecting after a network blip, fleet rollouts, market-open traffic spikes — raising QueueLength prevents the kernel from rejecting clients before your process sees them, avoiding cascading client retries. The default 1000 matches the Windows kernel default and is conservative for modern workloads; valid range goes up to 65535.
SkipIOCPOnSuccess : Boolean (default False)
What it does. When set to True, enables the FILE_SKIP_COMPLETION_PORT_ON_SUCCESS and FILE_SKIP_SET_EVENT_ON_HANDLE flags on the request queue handle via SetFileCompletionNotificationModes. The kernel then skips posting a completion packet to the IOCP when an overlapped I/O operation completes synchronously.
What it improves. Eliminates a kernel-to-user-mode hop on the hot request path when the call returns NO_ERROR synchronously — the worker dispatches the completion inline on the calling thread instead of waiting for an IOCP packet. This is the pattern Microsoft's reference "HTTP Server High Performance" sample uses. The default False is deliberate: enabling the flag requires caller-side handling of inline completions. The property is intended to be paired with OperatingMode = ompHighPerf in workloads where the throughput gain justifies the extra code path.
OperatingMode : TsgcHTTPAPIOperatingMode (default ompClassic)
What it does. Selects one of two accept/dispatch architectures:
ompClassic— single acceptor thread callsHttpReceiveHttpRequestsynchronously and hand-dispatches each request to the IOCP worker pool viaPostQueuedCompletionStatus. This is the historical behavior.ompHighPerf— implements Microsoft's reference "HTTP Server High Performance" pattern. The acceptor thread is removed entirely. At startup the server pre-postsThreadPoolSize × HighPerfAcceptsPerWorkerasync receives on the queue-bound IOCP (defaults to 32 × 4 = 128 concurrent outstanding receives). Each worker services its completion inline and re-posts another async receive, maintaining a sliding window until shutdown.
What it improves. ompHighPerf pays off when the server sees either deep single-stream pipelines (large-frame uploads/downloads) or many concurrent clients (hundreds to thousands). The pre-posted receive window absorbs bursts without per-connection allocation, and the inline dispatch removes the acceptor hand-off bottleneck. Leave the default ompClassic for low-traffic APIs and development environments — on light workloads the overhead of maintaining 128 pre-posted contexts costs more than it saves. The mode can be changed at construction time only; mixing modes within a single process lifetime is not supported.
HighPerfAcceptsPerWorker : Integer (default 4)
What it does. Controls how many async receives each IOCP worker pre-posts when OperatingMode = ompHighPerf. The value is ignored in ompClassic mode. The total number of concurrent outstanding receives the server maintains equals ThreadPoolSize × HighPerfAcceptsPerWorker.
What it improves. A deeper per-worker window lets the server absorb larger bursts of incoming requests without allocating new contexts on the hot path. Raise it for high-concurrency deployments (IoT fleets, market-data distribution, fan-out brokers); the tradeoff is memory — each pre-posted receive holds a request buffer (~16 KB) reserved until it completes. The default 4 is a conservative middle ground validated against the MSDN "HP" sample.
Example of Use
The following snippet configures an HTTP.sys server for a high-concurrency IoT backend: a large kernel queue to absorb reconnect storms, HighPerf dispatch with a widened pre-posted receive window, and inline-completion dispatch enabled.
uses sgcWebSocket_Server_HTTPAPI, sgcWebSocket_HTTPAPI_Server; // TsgcHTTPAPIOperatingMode var oServer: TsgcWSServer_HTTPAPI; begin oServer := TsgcWSServer_HTTPAPI.Create(nil); oServer.Host := '0.0.0.0'; oServer.Port := 8080; // absorb 10,000-device reconnect bursts before kernel-level 503 oServer.FineTune.QueueLength := 10000; // switch from single-acceptor to pre-posted IOCP workers oServer.FineTune.OperatingMode := ompHighPerf; // widen the per-worker pre-posted receive window (32 threads * 8 = 256) oServer.FineTune.HighPerfAcceptsPerWorker := 8; // dispatch inline on sync-success completions; skip the IOCP round-trip oServer.FineTune.SkipIOCPOnSuccess := True; oServer.Active := True; end;
For a typical internal or low-traffic API, leave every FineTune property at its default:
oServer := TsgcWSServer_HTTPAPI.Create(nil); oServer.Host := 'localhost'; oServer.Port := 8080; // FineTune defaults: QueueLength=1000, SkipIOCPOnSuccess=False, // OperatingMode=ompClassic, HighPerfAcceptsPerWorker=4 oServer.Active := True;
When you subscribe to the blog, we will send you an e-mail when there are new updates on the site so you wouldn't miss them.