
Met de OpenAI-API kun je je eigen AI-chats bouwen met ChatGPT Turbo. Met de sgcWebSockets-bibliotheek is het heel eenvoudig om met de API te interageren: bij een chatgesprek geeft het model een chat completion-respons terug.
ChatGPT Delphi-voorbeeld
OpenAI vereist dat je een request opbouwt waarin je de berichten doorgeeft die naar ChatGPT Turbo worden gestuurd, de temperature (om een meer of minder willekeurige output te krijgen)... hieronder een lijst met de beschikbare parameters.
- model: (verplicht) ID van het model dat je wilt gebruiken. Zie de compatibiliteitstabel van model-endpoints voor details over welke modellen met de Chat-API werken.
- messages: (verplicht) De berichten waarvoor chat-completions moeten worden gegenereerd, in chat-formaat.
- temperature: De te gebruiken sampling-temperatuur, tussen 0 en 2. Hogere waarden zoals 0,8 maken de output willekeuriger, lagere waarden zoals 0,2 maken hem gerichter en deterministischer.
- top_p: Een alternatief voor sampling op temperatuur, nucleus sampling genoemd, waarbij het model de tokens beschouwt waarvan de top_p-kansmassa optelt. 0,1 betekent dat alleen de tokens met de top 10% van de kansmassa worden meegenomen.
- n: Hoeveel chat-completion-keuzes er per input-bericht gegenereerd moeten worden.
- stream: Indien ingesteld worden gedeeltelijke message-deltas verstuurd, zoals in ChatGPT. Tokens worden verstuurd als data-only server-sent events zodra ze beschikbaar zijn, met de stream afgesloten door een data: [DONE]-bericht. Zie de OpenAI Cookbook voor voorbeeldcode.
- stop: Maximaal 4 sequenties waarbij de API stopt met het genereren van verdere tokens.
- max_tokens: Het maximaal aantal tokens dat in de chat-completion gegenereerd wordt. De totale lengte van input-tokens en gegenereerde tokens wordt beperkt door de context-lengte van het model.
- presence_penalty: Getal tussen -2,0 en 2,0. Positieve waarden bestraffen nieuwe tokens op basis van of ze al in de tekst zijn voorgekomen, waardoor het model eerder over nieuwe onderwerpen praat.
- frequency_penalty: Getal tussen -2,0 en 2,0. Positieve waarden bestraffen nieuwe tokens op basis van hun bestaande frequentie in de tekst, waardoor het model minder snel exact dezelfde regel herhaalt.
- logit_bias: Beïnvloedt de kans dat opgegeven tokens in de completion verschijnen. Accepteert een JSON-object dat tokens (gespecificeerd door hun token-ID in de tokenizer) koppelt aan een bias-waarde tussen -100 en 100. Wiskundig gezien wordt de bias opgeteld bij de logits die het model voor sampling genereert. Het exacte effect verschilt per model, maar waarden tussen -1 en 1 zouden de selectiekans moeten verlagen of verhogen; waarden zoals -100 of 100 zouden moeten leiden tot een ban of een exclusieve selectie van het betreffende token.
- user: Een unieke identifier voor je eindgebruiker, waarmee OpenAI misbruik kan monitoren en detecteren.
Hieronder vind je een eenvoudig voorbeeld waarin een bericht naar ChatGPT-Turbo wordt gestuurd.
procedure SendMessageChatGPT(const aMessage: string);
var
i: Integer;
oMessages: TsgcOpenAIArray_Request_Completion_Messages;
oMessage: TsgcOpenAIClass_Request_Completion_Message;
oRequest: TsgcOpenAIClass_Request_ChatCompletion;
oResponse: TsgcOpenAIClass_Response_ChatCompletion;
begin
oRequest := TsgcOpenAIClass_Request_ChatCompletion.Create;
Try
// ... model
oRequest.Model := 'gpt-3.5-turbo';
// ... create message
oMessage := TsgcOpenAIClass_Request_Completion_Message.Create;
oMessage.Content := aMessage;
oMessages := oRequest.Messages;
SetLength(oMessages, 1);
oMessages[0] := oMessage;
oRequest.Messages := oMessages;
// ... send message
oResponse := OpenAI.CreateChatCompletion(oRequest);
// ... process response
for i := 0 to Length(oResponse.Choices) - 1 do
DoLog('[' + oResponse.Choices[i]._Message.Role + '] ' + oResponse.Choices[i]._Message.Content);
Finally
oRequest.Free
End;
End;
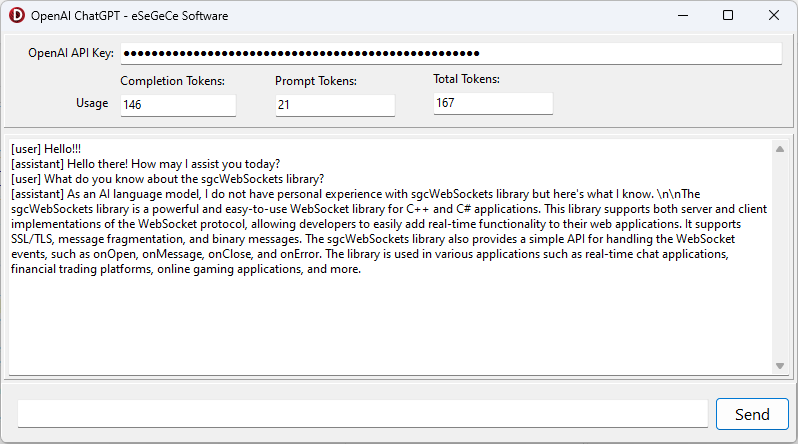
Hieronder vind je de gecompileerde demo voor Windows met de sgcWebSockets OpenAI Delphi-bibliotheek.